Published on: Feb 3, 2023
With the introduction of Artificial Intelligence (AI) in 6G networks, Machine Learning (ML) and Deep Learning (DL) approaches are increasingly utilized in wireless networks. Optimization problems in wireless networks are designed to enhance specific attributes of a user or a network. Consider a scenario where a user wants to receive the highest Signal-to-Interference and Noise Ratio (SINR) by optimizing the beamforming gain and power control. Addressing such problems can be done either using mathematical or novel machine learning approaches. Therefore, researchers have already started utilizing Reinforcement Learning (RL) techniques to improve the system performance in wireless networks.
But what does RL really do? To familiarize yourself with RL, stick to this blog post till the end!
Reinforcement Learning Elements
An RL approach has several elements [1, 2]:
- Agent: An agent is a single autonomous entity that can watch, perceive, and act by following its environment to accomplish its objective.
- State: What the agent perceives at a specific time t is referred to as a state and can be used to describe the environment.
- Action: After the agent perceives the state at time t, the action is conducted under the policy, resulting in the following state.
- Policy: The instruction that the agent uses to act and link the states to the actions is termed a policy.
- Environment: The environment is the simplification of properties of ML problems. The agent interacts with the environment.
- Reward: The goal is specified by a reward signal. At every time t, the environment provides the agent with a single number, or reward. The reward function is an indicator of the effectiveness of the action taken at time t.
- State-action value function: The reward function is an indicator of the effectiveness of the action taken at time t; however, the value function is the accumulated reward of a state in the long run.
In the majority of traditional Machine Learning (ML) techniques, the agent is instructed on what to perform and the appropriate course of action, but in RL, the agent must experiment with a variety of actions before eventually favoring the ones that appear to function the best [3].
Exploration and Exploitation Trade-Off
The goal of exploration is for the agent to learn more about various activities through exploring the environment. However, on the other hand, exploitation chooses the greedy approach to get the highest rewards by taking advantage of the agent’s current estimated value. The dilemma arises whenever the agent must decide between exploring and exploiting a situation. Of course, the easiest way to decide in this situation would be to act randomly. Greedy-epsilon is one of the techniques that leverages a value-based model to provide balance to this trade-off. The probability of exploring is described as epsilon in this context. With the greedy-epsilon approach, the agent exploits most of the time with a slight chance of exploring sometimes.
Defining the Problem
It’s important to carefully design the environment, policies, and rewards of the problem we want to be solved by RL. The policies that the environment interacts with will cause specific results which in the end will affect the reward function. A more detailed description of the policy is provided in the following.
Policy
The policy is the brain of the RL approach. It decides what reward a specific task gets. In wireless networks, we are dealing with model-free scenarios. In the next section we explain more about what model-free means, while here we explain more about the different policies for the model-free RL approaches. There are three different kinds of model-free RL approaches that define the reward function [4].
-
- Value-based RL: In this approach, only a value function is kept rather than an explicit policy. Therefore, the policy is implicit and can be inferred straight from the value function. In other words, value-based RL takes a greedy approach to assign the best value to action.
- Policy-based RL: In a policy-based approach, a policy is built to map the states to the actions and this policy is preserved through the whole learning process.
- Actor-Critic Network: This approach is a mix of value-based and policy-based RL. The actor takes actions using the policy gradient approach and the critic network evaluates how good the action was according to a value-based approach.
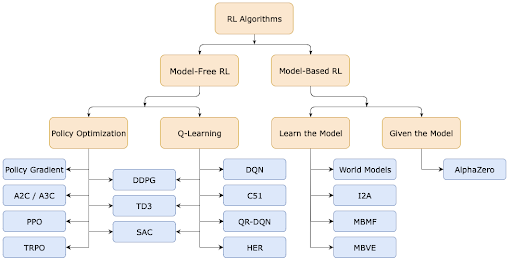
Fig 1. Different kinds of model-free RL approaches [5]
Why Deep RL?
As shown in Fig. 2, RL algorithms are categorized into two large groups, named model-based, and model-free RL approaches. Checking whether the agent has access to (or learns from) a model of the environment determines whether an algorithm should be categorized as model-based or model-free.
We mostly deal with model-free environments in our everyday life, especially in wireless networks. One of the main justifications for using RL in wireless networks is the model-free environment, which implies we don’t have a channel model.
One of the well-known model-free learning algorithms is Q-learning. Q-learning involves experimentation, but it also includes an extensive exploring phase. In other words, Q-learning engages in risky actions during the exploration phase before arriving at a higher probability during the exploitation phase, as we previously explained. However, in order to calculate these Q values (also known as action values, or expected future returns), we must first record the prior Q values in a table. If the state and action spaces are huge, as they typically are in wireless systems, the problem becomes more challenging to solve. Fit-curving is an option in order to deal with the mentioned large amount of data. Consider a sizable Q table as a large data set that a function can fit onto it. Sometimes, a linear function can be the best fit, but this is typically not the case. That’s why we need a filter, and this is when the neural networks come in handy since they are good at function representations. As a result, deep neural networks suit to be the driver of RL [5].
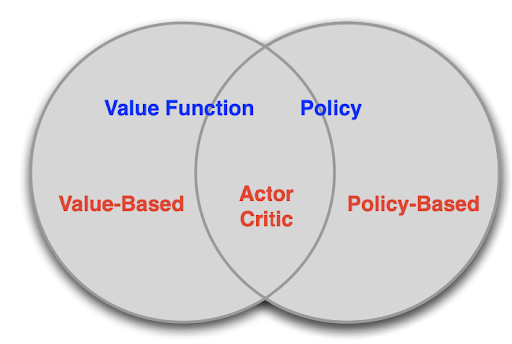
Fig 2. A classification of different RL approaches [3]
Conclusion
AI is becoming an inseparable part of our future world, especially regarding wireless networks. In the envisioned 6G technology, more devices are expected to be connected. Finding approaches to connect devices intelligently is one of the major goals of 6G, which can be made feasible with machine/deep learning approaches. In this blog post, we introduced Reinforcement Learning (RL) as a potential enabler of 6G AI-driven technologies, and we briefly discussed how this technique works.
If you were able to stick until the end and can’t wait for more content and you also want to know about us and our projects, you can always follow our social media channels.
References
[1] R. S. Sutton and A. G. Barto, Introduction to Reinforcement Learning. Cambridge, MA, USA: MIT Press, 1998
[2] M. Liu and R. Wang, “Deep reinforcement learning based dynamic power and beamforming design for time-varying wireless downlink interference channel,” arXiv.org, 07-Nov-2020. [Online]. Available: https://arxiv.org/abs/2011.03780
[3] https://spinningup.openai.com/en/latest/spinningup/rl_intro2.html#a-taxonomy-of-rl-algorithms
[4] https://www.davidsilver.uk/wp-content/uploads/2020/03/pg.pdf
[5] https://youtu.be/dWZyXRBYQ-Y



